

Xiao Fan (范潇)
Senior student @ Tongji University
Interests: Test-time Adaptation, Self-Evolving Embodied Agent
xiaofan140@gmail.com · Google Scholar · GitHub · WeChat · X
Education¶
| Degree | Institution | Advisor | Years |
|---|---|---|---|
| B.Eng. in Data Science | Tongji University | 2022–2026 | |
| D.Eng. in Electronic Information | Tsinghua University | Prof. Zhi Wang | 2026–2031 |
Recent News
- [2025-09] My personal website is launched!
- [2025-09] We have released a new paper VERL on Reinforcement Learning for reasoning LLM.
- [2025-11] My debut paper, as the sole first author, has been accepted by AAAI 2026 (CCF-A, 17.6% overall acceptance rate)!
- [2026-04] VERL has been accepted as ACL 2026 Findings.
Publications¶
* equal contribution, † corresponding author.
2025¶
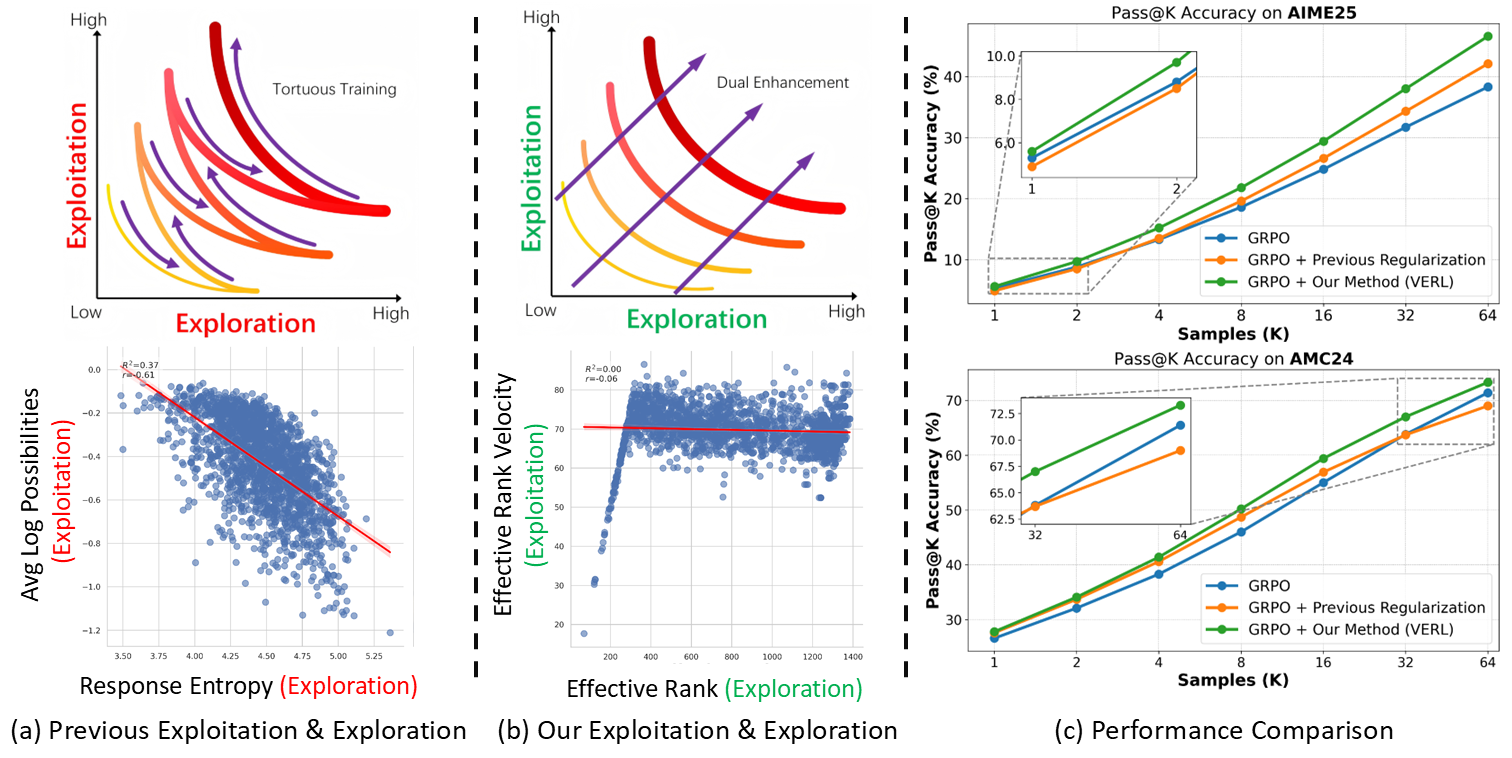 Semantic-Space Exploration and Exploitation in RLVR for LLM Reasoning
Semantic-Space Exploration and Exploitation in RLVR for LLM Reasoning
Fanding Huang*, Guanbo Huang*, Xiao Fan, Yi He, Xiao Liang, Xiao Chen, Qinting Jiang, Faisal Nadeem Khan, Jingyan Jiang†, Zhi Wang†.
Accepted as ACL 2026 Findings.
[Paper] [Code] [Project] [BibTex]
Abstract
Reinforcement Learning with Verifiable Rewards (RLVR) for LLM reasoning is often framed as balancing exploration and exploitation in action space, typically operationalized with token-level proxies (e.g., output entropy or confidence). We argue that this apparent trade-off is largely a measurement artifact: token-level statistics reflect next-token uncertainty rather than how reasoning progresses over multi-token semantic structures. We therefore study exploration and exploitation in the hidden-state space of response trajectories. We use Effective Rank (ER) to quantify representational exploration and introduce its temporal derivatives, Effective Rank Velocity (ERV) and Effective Rank Acceleration (ERA), to characterize exploitative refinement dynamics. Empirically and theoretically, ER and ERV exhibit near-zero correlation in semantic space, suggesting the two capacities can be improved simultaneously. Motivated by this, we propose Velocity-Exploiting Rank Learning (VERL), which shapes the RL advantage with an auxiliary signal derived from ER/ERV and uses the more stable ERA as a meta-control variable to adaptively balance the incentives. Across multiple base models, RL algorithms, and reasoning benchmarks, VERL yields consistent improvements, including large gains on challenging tasks (e.g., 21.4% in Gaokao 2024).
2026¶

MoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm
Xiao Fan, Jingyan Jiang†, Zhaoru Chen, Fanding Huang, Xiao Chen, Qinting Jiang, Bowen Zhang, Xing Tang, Zhi Wang.
Accepted by AAAI 2026 (CCF-A, 17.6% overall acceptance rate).
[Paper] [Code] [BibTex] [Poster]
Abstract
Test-Time Adaptation (TTA) has proven effective in mitigating performance drops under single-domain distribution shifts by updating model parameters during inference. However, real-world deployments often involve mixed distribution shifts, where test samples are affected by diverse and potentially conflicting domain factors, posing significant challenges even for state-of-the-art TTA methods. A key limitation in existing approaches is their reliance on a unified adaptation path, which fails to account for the fact that optimal gradient directions can vary significantly across different domains. Moreover, current benchmarks focus only on synthetic or homogeneous shifts, failing to capture the complexity of real-world heterogeneous mixed distribution shifts. To address this, we propose MoETTA, a novel entropy-based TTA framework that integrates the Mixture-of-Experts (MoE) architecture. Rather than enforcing a single parameter update rule for all test samples, MoETTA introduces a set of structurally decoupled experts, enabling adaptation along diverse gradient directions. This design allows the model to better accommodate heterogeneous shifts through flexible and disentangled parameter updates. To simulate realistic deployment conditions, we introduce two new benchmarks: potpourri and potpourri+. While classical settings focus solely on synthetic corruptions (i.e., ImageNet-C), potpourri encompasses a broader range of domain shifts—including natural, artistic, and adversarial distortions—capturing more realistic deployment challenges. Additionally, potpourri+ further includes source-domain samples to evaluate robustness against catastrophic forgetting. Extensive experiments across three mixed distribution shifts settings show that MoETTA consistently outperforms strong baselines, establishing new state-of-the-art performance and highlighting the benefit of modeling multiple adaptation directions via expert-level diversity.
Projects¶
- I promise I will soon organize and share my past projects.
Service¶
- Sadly, nothing to serve yet.